The Forth Lisp Python Continuum (Flpc) can now compile its own source code! Get it from Github.
So instead of
$ python compiler.py file1.flpc file2.flpc file3.flpc > output.f
you can now run
$ ./flpc precompiled/compiler.f
> push: output.f init_g
> push: file1.flpc compile_file
> push: file2.flpc compile_file
> push: file3.flpc compile_file
To have the compiler compile its own source code, run
$ ./flpc precompiled/self.f
This compiles the sources lib/stage{0,1{a,b,b2,b3,c,d},3{a,b}}.flpc lib/flpc_grammar.flpc lib/stage6{a,b}.flpc test/self.flpc into gen/output.f (the subdirectory gen must exist). Check with diff -iwB precompiled/self.f gen/output.f to see that the two files are the same!
This produces a .f file that can then be fed back into ./flpc for execution. Recall that
.flpc files are thought of as the FlpcPython source.f files are human-readable and -writable FlpcForth "bytecode" [bytecode]./flpc executes this bytescode and is produced from flpc.c (using gcc or tcc)Since one aim of Flpc is to have as much of its language features added at runtime (as opposed to adding these features to its bytecode interpreter flpc.c), it made writing its own compiler more difficult.
(All envisioned interactive sessions in this section are fictional and not yet implemented.)
Now instead of a typing FlpcForth at the interpreter's prompt, we should soon be able to type in FlpcPython directly. Something like
>> print(x + 1)
instead of
> pick: x 1 + print
More importantly, it will now finally be possible to modify the language syntax at runtime in the interpreter. Something like
>> grammar_eval("make_resizable = '{' {exprs} '}')
>> grammar_eval("non_block_non_infix = make_resizable | forth | func_call
| name_quote | quote | parenthesis
| NUMBER | STRING | variable")
>> tprint({3 2 1 3})
{3 2 1}
See the flpc.grammar for the grammar we start with and pymetaterp for the (initial) semantics of the grammar itself. Reassigning a rule (=) as we did here with non_block_non_infix would override the previous grammar rule.
Afterwards, its probably a good time to cleanup some of the hacks that were needed to get to this point.
So it only took ~2 years instead of the original estimated 3 weeks to complete "stage6", the last stage needed to become self hosted? All we had to do was translate the 350 lines of Python in compiler.py into Flpc. On the other hand it ended up translating to about 700+ lines of Flpc which is as much as all the other stages combined!
Being able to interpret FlpcForth at breakpoints was helpful but I needed to do too much mental gymnastics to formulate my queries. And the relatively slow running speed (33s for to reach the final stage) made it hard to edit and debug.
I've added an extra position-translating map that would show me the FlpcPython source in the stack trace. So instead of something like
we see
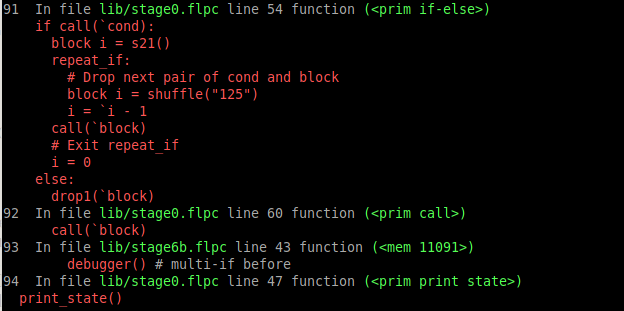
The map is just a text file emitted by compiler.py that looks like
236 lib/stage0.flpc 3 5
238 lib/stage0.flpc 5 22
255 lib/stage0.flpc 22 36
269 lib/stage0.flpc 36 38
271 lib/stage0.flpc 38 55
288 lib/stage0.flpc 55 61
294 lib/stage0.flpc 61 75
308 lib/stage0.flpc 128 292
Each line contains token_index filename start end maps the token_indexth space-separated word/token of the bytecode source to the range of characters from start to end in the file filename.
For example the source print(1 + 1) compiles to 1 1 + print, + in the latter is the third token and maps to the 7th to 11th character.
print(1 + 1)
123456789abc
(Actual counts are zero-indexed and token index also account for the boot.flpc that's pre-compiled and written to memory using init_memory.dat each time ./flpc starts.)
I thought about many ways around the speed issue. Many died at the thought experiment stage. Finally, I added hash tables with open addressing which turned out to be less complicated (both in terms of understanding what's going on and complexity added to the internal memory representation) than I thought. I converted both internal function names lookup names.get (in stage1b2.flpc) and object attribute lookup obj . attrib (in stage1b3.flpc) to use hash tables.
Right now it takes about 110s to compile the compiler itself.
I might write more about this later.
Some more asserts and tests were added since some errors took a long time to debug as the observed effects were far from where they occured. This probably make parts less polymorphic/open to (re)interpretation but hopefully not too much.
It was painful to try to mimic some of Python's effect to translate compiler.py to Flpc. In the add, a lot of Python features like list comprehension and lazy evaluation boolean operators were added. However, some of the syntaz was clunky such as
lazy_and([condition_1] condition2)
(imagine trying to chain many of these together) while others had much more limited scope such as the following implementation of string interpolation. (Normally made up of some templating syntax like The result of {foo} added to {bar} is {foo + bar} that fills in the value of expressions.)
dprint <- fun[title value]:
print(title)
tprint(value)
printeol()
dprint only accepts exactly two values: a string and a value, and prints them one after the other! But it was still good enough and much better than writing all
One problem that didn't happen: running out of memory. I thought with all the new objects we were allocating for AST nodes for compilation would run us out but even running the current compiler on itself, it seem that only ~8.6 million memory cells are used.
And, of course, I've gone from being time rich to time poor to borrow akkartik's phrasing, which is probably the most signifcant factor contributing to slow progress.
flpc.c is compiled using gcc which itself is huge but we can also compile it with tcc which is much smaller. However as mentioned earlier, flpc.c is written with the possibility of (manually) converting it to x86_64 assembly in mind (see forth_tutorial for a proof of concept). And writing an assembler in Flpc itself is easier than writing a C compiler, especially if the assembler only needs to assemble the subset of instructions used to write the Flpc bytecode interpreter (we could use our assembly debugger as a REPL to make writing this faster).
Currently, the self-hosted Flpc compiler (as opposed to compiler.py) does not write a bytecode-to-source position map.
There's still a memoizer in the C code we're using. We can probably replace it with a hashtable now that they are implemented.
[bytecode] I think bytecode usually means bytes representing instructions. FlpcForth is a language and not bytes, though every space-delimited string token is eventually replaced by a 64-bit int representing either a primitive call, a function call or a value.
Posted on Apr 19, 2020